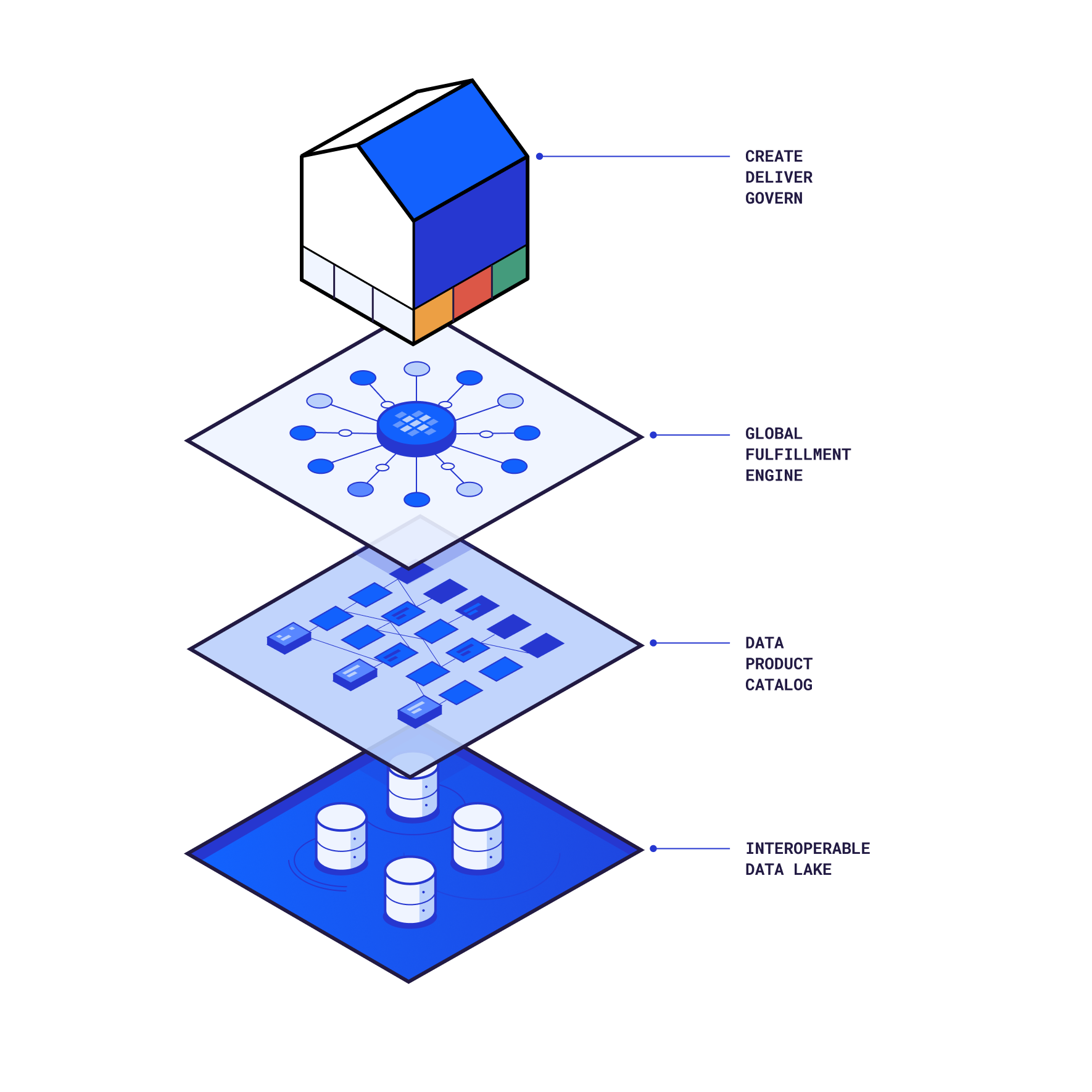
Bobsled is a modern data fulfillment platform that helps teams share, deliver, and customize datasets across clouds, regions, and tools—without the complexity of traditional pipelines.
At its core, Bobsled turns raw or refined data into Data Products that can be shared with internal teams, partners, or customers—without maintaining pipelines, worrying about replication logic, or managing infrastructure.
Why does Bobsled exist?
Organizations increasingly need to deliver data:
Across cloud providers
Between analytics platforms
To internal teams or external customers
Most solutions either involve hand-rolled pipelines or brittle integrations. Bobsled replaces that with an opinionated, infrastructure-aware approach:
No-code for non-engineers
Fully automated for engineers
Cloud-native and region-aware
You don’t have to choose between flexibility and simplicity.
Why build with Bobsled?
Global connections: Share analytics-ready data directly to external teams anywhere in the cloud.
Zero-copy data products: Build and share logical views of a common data asset without replication.
Egress-free infrastructure: Never pay egress to share data from Bobsled.
Point-and-click UI: Empower non-technical stakeholders to customize and deliver data products.
Powerful APIs: Integrate data sharing into an existing pipeline or app.
Pre-built Integrations: Sync “gold” data assets from your data warehouse or file storage into Bobsled instantly.
What can you build?
Scalable, cost-efficient data feeds customers and partners love.
Cloud Data Feeds | Customize and share Data Products to customers natively in their Data Warehouse or File Storage. |
Out-of-app Analytics | Enable users to access and analyze application data in their data platform. |
Automated fulfillment | Automate data fulfillment by integrating data sharing into a workflow or marketplace. |
Two Ways to Use Bobsled
Bobsled has two core modes of operation. Which one you use depends on whether you want us to manage a replica of your data or simply move it directly.
1. Sledhouse (Managed replication and distribution)
Bobsled creates and maintains a Sledhouse Table—a golden, analytics-ready copy of your source data stored in our infrastructure. From there, you can:
Keep it in sync on a schedule you define
Create Data Products (filtered or transformed subsets) without touching the source
Fulfill those Data Products to destinations like Snowflake, Databricks, BigQuery, S3, or GCS
Optionally use Local Copies for performance-friendly, in-region delivery
Because the data is already staged in Sledhouse, fulfillment is fast, consistent, and doesn’t repeatedly pull from your source.
2. Transfers (Data pipeline)
For cases where you don’t want a managed replica, Bobsled can move data directly from source to destination via a Bobsled Share. You still get:
Flexible pipeline configuration
Automatic format conversion
Scheduling and monitoring in the same UI
Logging, error handling, and retries
In Transfers, each pipeline is self-contained—you configure every source-to-destination share yourself. There’s no persistent copy in between, so each fulfillment pulls from the source at run time.
Explore our documentation to learn how to implement Bobsled across your data stack—from Sledhouse quickstart guide to navigating the application.