This article explains how to access data delivered to an Amazon S3 destination managed by Bobsled. The examples below show how to access data using a command-line interface (CLI) within the data consumer's environment. This method is useful for browsing, copying, or syncing files from the Bobsled-managed bucket to a consumer-owned S3 bucket.
While these examples use the CLI, data can also be accessed programmatically or integrated into production pipelines using any Amazon S3-compatible client—so long as the requesting account has been granted permission to access the destination.
Prerequisites
Before consuming a data transfer:
In Bobsled Transfers, before consuming a data transfer, the data must be sent to the destination, and access must be configured in Bobsled for the identity consuming the data. To learn how to configure access to the destination, please visit the Amazon S3 destination.
In Bobsled Sledhouse, at least one Data Product must have been shared to the destination.
If you are accessing the data via the AWS command-line tool, you must install the CLI.
NOTE:
Please ensure that the consumer’s IAM policy includes the necessary permissions for listing and reading from an S3 bucket. If the policy requires specifying buckets that a user/role can access, the destination bucket ARN and access point ARN should be included as a resource in the consumer’s policy that at the least, has the following permissions:
s3:GetObject: Read objects from the bucket.
s3:ListBucket: List objects within the bucket.
s3:GetBucketLocation: determine the geographical location of an S3 bucket.
Learn more about help finding the destination bucket ARN in Amazon S3 ↗
Sample Policy:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowListBucketAndGetLocation", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": [ "{S3_BUCKET_ARN}", "{ACCESS_POINT_ARN}" ] }, { "Sid": "AllowGetObject", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectAttributes", "s3:GetObjectVersion", "s3:GetObjectTagging" ], "Resource": [ "{S3_BUCKET_ARN}/*", "{ACCESS_POINT_ARN}/object/*" ] } ] }
The bucket and access point ARNs can be found in the UI for a given share by selecting Access Data → Advanced
Accessing a data transfer via a Share in Bobsled transfers
From the Shares list page, click on the share that you would like to access.
Once a data transfer in the share has been completed, select the button Access Data.
Select the copy icon and send it to your data customer.

Option 1: Accessing Data via Web Console
Consumers can easily access the data using the web console link to view and download the data.
Select the Web console tab in the access dialog.
Copy the AWS Web Console link icon and send it to your customer. They will be prompted to log in to their AWS console if they are not already.
Option 2: Accessing Data via Command Line
Using the AWS command-line tool, consumers can list, copy, and sync the contents of the data transfer in Amazon S3. Bobsled provides out-of-the-box list, copy, and sync commands tailored to the data consumer's bucket.
TIP:
For the following commands, please ensure that all S3 URIs (Bobsled URL and your bucket path) are enclosed in quote (‘‘) if any spaces in the URI exist.
Step 1: Log In to the CLI
Run the command
aws configure. You will be prompted on the CLI to enter your AWS Access Key ID, AWS Secret Access Key, default region, and output format.For the default region, be sure that it is set to the same region as in the Bobsled share.
Set the output format to JSON
aws configure AWS Access Key ID [********************]: AWS Secret Access Key [********************]: Default region name [us-east-1]: Default output format [json]:
Step 2: List the contents
Please visit AWS CLI ↗ for more information.
Required if Requester pays is enabled for the bucket:
--request-payer requester
Additional parameters to use with the list command:
--recursive(boolean) Command is performed on all files or objects under the specified directory or prefix--human-readable(boolean) Display file sizes in human-readable format--summarize(boolean)Displays summary information such as the number of objects, total size, etc.
aws s3 ls <Bobsled URL> --request-payer requesteraws s3 ls <Bobsled URL> --recursive --human-readable --summarize --request-payer requesterStep 3: Copy the contents to your bucket
Please visit AWS CLI ↗ for more information.
NOTE:
To copy data into your own S3 bucket, the bucket must be in the same region as the Bobsled-managed bucket. If the region is not the same, you will receive an ‘Access Denied’ error.
Copy an individual file:
aws s3 cp < Bobsled URL/<path to file> s3://<your bucket or path> --request-payer requesterCopy all files:
--recursive(boolean) Command is performed on all files or objects under the specified directory or prefix. Visit AWS CLI cp command document linked above for more information..aws s3 cp <Bobsled URL> s3://<your bucket or path> --recursive --request-payer requester
NOTE:
The command line --resquest-payer requester flag is only required if Requester Pays was enabled during setup. If not, it will result in a 403 error. If you’re unsure, please contact your administrator or support.
Step 4: Sync the contents
Use sync if you would like to copy only files that are new or updated. Please visit AWS CLI ↗ for more information.
aws s3 sync <Bobsled URL> s3://<your bucket or path> --request-payer requesterNOTE:
The command line --resquest-payer requester flag is only required if Requester Pays was enabled during setup. If not, it will result in a 403 error. If you’re unsure, please contact your administrator or support.
Accessing Data Products via Data Fulfillment in Sledhouse
From the Data Fulfillment list page, click on the Data Consumer whose that you would like to see the access details.
Once a data share has been completed, select the button Access Data.
Select the copy icon and send it to your data customer. Additionally, you can follow the steps relayed in Bobsled Transfers details.
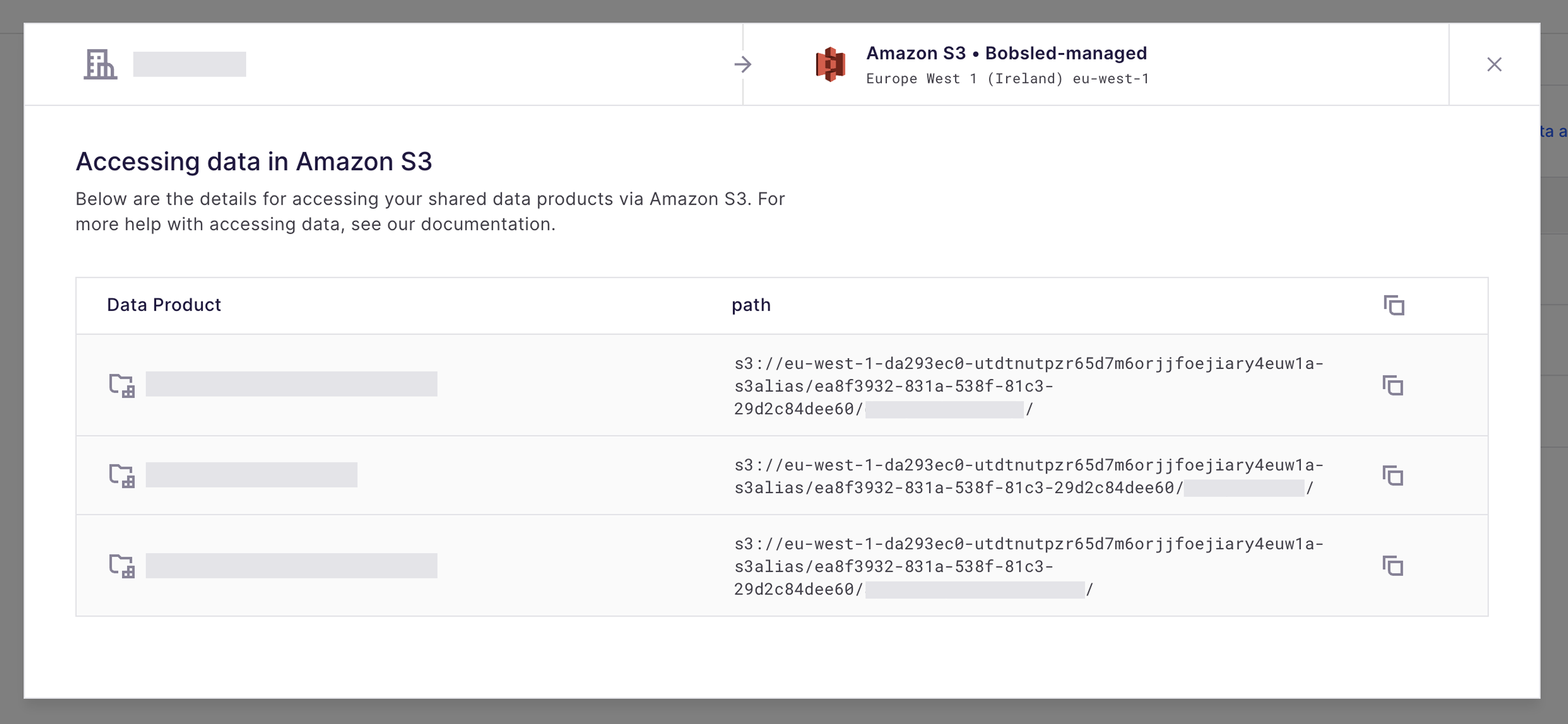
NOTE:
• Using Bobsled Sledhouse Data Fulfillment functionality, Bobsled will provide the discrete paths for any individual Data Products rather than a single bucket.